

Audio Mixing Techniques for Pro-Level Podcasts & Video
Meta title: Audio Mixing Techniques for Pro Podcasts
Meta description: Learn audio mixing techniques that make podcasts and video sound polished, clear, and consistent across every listening environment.
URL slug: /audio-mixing-techniques-for-podcasts-video
Primary keyword: audio mixing techniques
Secondary keywords: podcast audio mixing, professional podcast editing, video audio post-production
You've done the hard part already. You booked guests, shaped the story, recorded the video, and maybe even nailed the visual brand. Then playback starts, and the illusion breaks. The voice is thin. The music steps on the dialogue. One speaker sounds close, the other sounds distant, and the whole episode feels less premium than it looks.
That's where audio mixing techniques stop being “post-production stuff” and start becoming brand strategy. A polished mix tells your audience that you care about details, consistency, and how your content lands in real life. If you're recording remotely, capturing screen demos, or patching together multiple sources, even basic setup discipline matters. For creators handling those workflows, Smooth Capture's audio tips are a useful reminder that clean capture upstream makes every mixing decision easier downstream.
From Good Content to Great Audio
You publish an episode that looks sharp, the guest is strong, the story works, and the edit moves. Then playback starts on a phone speaker or in a car, and the production value drops fast. Voices feel uneven. Music crowds the message. The content is good, but the sound tells a different story.
A strong mix presents that content with control. For podcasters and video creators, that matters well beyond engineering pride. Audio quality shapes whether your brand feels considered, expensive, and trustworthy, or rushed and disposable.
The mistake I see from ambitious teams is treating mixing like a final cosmetic pass. It is a decision-making process. Level balance, EQ, dynamics, noise control, music placement, and loudness all affect whether the audience stays focused on the message or starts noticing problems. The goal is not flashy processing. The goal is to make every source feel intentional and every transition feel natural.
That matters even more in creator workflows than in generic music tutorials. A podcast or video mix has to protect speech first, survive inconsistent recording setups, and translate across laptops, earbuds, cars, and social clips. If your production includes remote guests, screen recordings, or multiple capture paths, Smooth Capture's audio tips are a useful reminder that cleaner source audio gives the mixer better options later.
Professional teams build around order. Clean the recording. Set the hierarchy. Control dynamics. Fit music and effects around the voice. Then test the result in real listening conditions. That workflow is what turns decent raw material into a polished show people can listen to for an hour without fatigue, which directly supports podcast audience growth strategies that keep listeners coming back.
At Flexwork, we treat mixing as part of brand execution. If the picture says premium and the audio says homemade, the audience feels the mismatch immediately. Great content deserves a mix that keeps the promise your visuals already made.
Why Your Audio Quality Is Limiting Your Growth
Weak audio doesn't just sound amateur. It creates friction.
A listener may never tell you why they stopped an episode halfway through, but the reasons are familiar inside the control room. Harsh consonants. Jumps in volume between speakers. Music that feels exciting on studio headphones but turns muddy on a phone. These problems don't always register as “bad production” in the audience's mind. They register as effort. If listening feels like work, people leave.
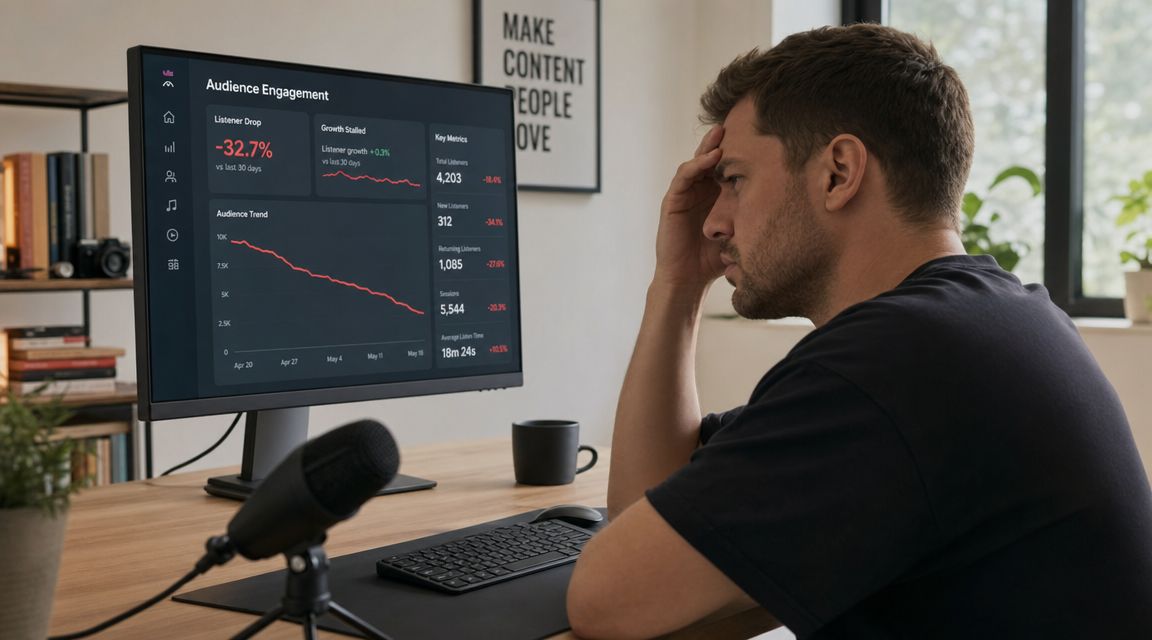
Your audience isn't listening in a studio
The biggest mistake I see is mixing as if everyone listens in ideal conditions. They don't. Edison Research reported that 67% of the U.S. population ages 12+ had listened to a podcast, and YouTube has said over 1 billion people watch podcasts monthly, which means your audio has to survive platform compression and playback on small mobile speakers, not just expensive headphones or studio monitors, as noted in this podcast listening discussion.
That changes the standard. You're not mixing for a perfect room. You're mixing for earbuds, cars, laptops, office speakers, and phones.
DIY burnout sounds like inconsistency
Most creators can learn editing basics. Fewer can maintain consistent results week after week.
That's the hidden cost of DIY post. You spend late nights trying to solve a vocal harshness problem with random EQ moves, then over-correct the next episode because a different guest has a different tone. You chase the sound instead of designing a repeatable process.
Common symptoms show up fast:
- Uneven dialogue: One host sounds forward and confident, the other sounds buried.
- Aggressive top end: Speech feels sharp, especially on “s,” “sh,” and “ch” sounds.
- Music masking: Intros and beds compete with the voice instead of supporting it.
- Export inconsistency: One episode feels dense and polished, the next feels thin and undercooked.
If you're trying to grow a show, that inconsistency works against every other effort. Better guest strategy, stronger thumbnails, and a smarter content calendar can't fully offset an experience that feels rough once someone hits play. That's one reason creators focused on growth should also think about listener retention habits and platform strategy together. Flexwork's guide on how to get more podcast listeners connects that broader growth picture well.
Good content earns a click. Good sound earns the next minute.
“Good enough” usually fails on translation
Translation is the ultimate test. A mix that feels warm and full in one environment can collapse somewhere else.
For speech-first content, this is especially unforgiving because the voice carries the whole product. If the listener misses key words, strains during level swings, or turns the volume up and down during a commute, your production is asking too much from them. At that point, audio quality isn't a technical flaw. It's a brand leak.
The Professional Shortcut to Flawless Sound
The gap between a capable DIY mix and a reliable professional result usually comes down to systems, not talent.
Professional mixers don't win because they know one magic plugin. They win because they organize sessions properly, make fewer emotional decisions, and solve problems before those problems stack. That matters when an episode includes multiple microphones, music, ads, remote guests, room tone differences, and platform-specific deliverables.

What professionals handle that creators often underestimate
Professional mixing involves bussing tracks into logical groups and using parallel compression, where a heavily compressed copy blends back with the original to add density while preserving impact, according to this explanation of advanced mix architecture. That sentence sounds technical, but the benefit is simple. The mix stays controlled without sounding flat.
A creator working alone usually hears only the final problem. A professional hears the routing issue, the dynamic issue, and the translation issue behind it.
A typical pro workflow covers things like:
- Session organization: Grouping dialogue, music, FX, and alternate takes so revisions stay manageable.
- Shared processing: Using sends and buses instead of stacking duplicate plugins on every track.
- Parallel control: Adding energy and consistency without crushing the life out of speech.
- Revision speed: Adjusting one subgroup instead of rebuilding the entire mix.
Why outsourcing can be the faster creative move
There's a point where doing it yourself stops being efficient.
If your time is better spent on hosting, sales, audience development, or content strategy, handing off post-production is often the cleaner decision. One practical route is using a dedicated audio editing service for the mix and cleanup stage so the release process stops bottlenecking around technical work.
For creators who also make music-adjacent content, interview shows with performance segments, or branded media that crosses between speech and musical elements, this guide for music artists and producers is a useful side read because it shows how production tools fit into a larger workflow rather than acting as shortcuts by themselves.
Where a production partner fits
Flexwork Podcast Studios offers studio recording and post-production support, including sound mixing for podcast projects, which is useful for creators who want one team handling both capture and cleanup. That kind of setup is often more valuable than a pile of standalone tools because the recording choices and the mixing choices support each other.
The fastest way to get a professional sound is to stop rebuilding your process every episode.
If you're publishing regularly, consistency becomes the product. That's the true shortcut. Not less care. Better systems.
The Foundational Audio Mixing Workflow
A creator records a sharp interview on a good camera, cuts the video well, publishes on schedule, and still sounds smaller than competitors with less interesting ideas. The usual reason is not the microphone alone. It is the mix. For podcasters and video teams, mixing is the stage where clean recordings become a brand asset instead of just usable audio.
Modern editing made that possible by separating recording from mix decisions. Engineers have worked this way since multitrack production changed post-production from simple balance moves into a deliberate craft. Spoken-word production uses the same logic, but the target is different from music. The job is not to impress another engineer. The job is to make dialogue feel expensive, clear, and reliable across earbuds, laptops, car speakers, and social clips.
The broad workflow looks like this:

Prepare and organize your session
The mix starts with triage.
Before EQ, compression, or loudness targets, get the session into a state where decisions are obvious. Label every source clearly. Split hosts, guests, music, ads, pickups, and room tone into their own tracks or groups. Remove dead air you know will not survive the edit, obvious false starts, and any duplicate takes that only create confusion later. If this is tied to video, confirm the picture edit is stable enough that you are not rebuilding sync halfway through the audio pass.
This step is less about tidiness and more about speed under revision. A clean session lets you respond to client notes quickly, swap in pickups without breaking routing, and keep tone consistent from episode to episode. That consistency matters for brand perception. Viewers forgive a lot in video. They are much less forgiving when speech feels messy or tiring.
Useful habits here include:
- Name tracks for function, not convenience: “Host,” “Guest Remote,” and “Sponsor VO” are better than “Audio 1.”
- Color-code by role: Keep dialogue, music, and effects visually separate.
- Build buses early: Route dialogue, music, and sound design to subgroups before processing.
- Leave session notes: Mark pronunciation fixes, retakes, and any section that needs manual automation.
Flexwork breaks this stage down well in its guide to post-production best practices for podcast episodes.
Session rule: If the routing is not obvious at a glance, revisions get slower and errors get easier to miss.
Set your levels with gain staging
A stable mix begins with level discipline.
Start with clip gain, region gain, or input trim so every speaker hits your chain in a sensible range. One guest may arrive 12 dB lower than everyone else. Another may be recorded too hot and already sound strained. Those are source problems first. If you push everything into a compressor or limiter before correcting the input level, the processing reacts inconsistently and the voice gets harder to control.
This is one of the big differences between hobby mixing and professional spoken-word work. Music tutorials often focus on tone before balance. In podcasts and creator video, level relationships usually decide whether the audience stays with you. A listener should never need to reach for the volume control because one answer drops out and the next sentence jumps forward.
A quick comparison helps:
| Problem | Common shortcut | Better approach |
|---|---|---|
| Quiet guest track | Add output gain on the mix bus | Raise clip gain first, reduce noise carefully, then rebalance |
| Loud host mic | Hit it with heavy compression | Lower the source level, then compress with intention |
| Music covering dialogue | Pull the whole bed down | Automate around speech and rebalance the music bus |
For creators building niche formats, the same discipline applies in unusual content categories. Teams that automate faceless ASMR videos still need careful gain staging because whisper content falls apart fast when noise floor, breaths, and transient detail are left unmanaged.
Sculpt your sound with corrective EQ
Corrective EQ solves problems the listener can feel even when they cannot name them.
For podcasts and video, the first EQ moves are usually subtractive. Remove low-end rumble that eats headroom. Cut a bit of boxiness if the room makes the voice feel trapped. Ease harsh upper mids when a microphone or untreated space turns consonants into fatigue. These are small moves, but they do serious work because spoken-word mixes live or die on intelligibility.
Restraint matters. A broad high-frequency boost can make a voice sound exciting for ten seconds, then abrasive for forty minutes. Aggressive mid cuts can create a slick first impression, then leave the speaker sounding thin and less authoritative. The right move depends on context. A solo voice for a sales video can carry more polish. A dense interview with music under it often needs less hype and more space management.
Three reliable EQ decisions:
- Remove what does not serve the message. Rumble, HVAC buildup, and muddy low mids reduce clarity.
- Cut specific problems before shaping tone. Narrow fixes usually preserve the natural voice better.
- Check changes in context. A vocal that seems plain by itself may sit perfectly once music and ambience come back in.
Music masking is the other issue many creator tutorials miss. If background music fights the voice, lowering the bed is only one option. Often the better choice is a modest EQ pocket in the music bus so the narration stays forward without making the soundtrack feel timid.
A visual example can help if you want to compare your own workflow against a broader mixing process:
Control dynamics for consistent volume
Compression makes speech feel finished when it is used with judgment.
The goal is consistent presence. You want the listener to catch every word without hearing the compressor work. That usually means moderate settings, sensible attack and release choices, and manual automation on the lines that still jump out. One host may need gentle control with plenty of transient detail left intact. A remote guest with uneven mic technique may need more active shaping plus a few hand-drawn rides.
Trade-offs matter here. Push compression too hard and the voice gets flat, small, and tiring. Use too little and the mix feels amateur because every sentence lands at a different apparent volume. The right result sounds calm and controlled, not processed.
What works in practice:
- Moderate compression on dialogue: Control peaks while keeping expression.
- Manual rides after compression: Catch words or phrases that still poke out.
- Voice-specific settings: Fast, bright voices and soft, breathy voices rarely want the same treatment.
What causes problems:
- Heavy compression across the full mix: Listener fatigue builds quickly.
- One preset on every speaker: Different mics, rooms, and delivery styles need different settings.
- Chasing final loudness too early: If the dynamics are wrong, louder exports only magnify the flaws.
A strong spoken-word mix disappears in use. The audience follows the idea, trusts the presentation, and connects the sound with the quality of the brand on screen.
Advanced Techniques for a Signature Sound
Once the foundation is solid, the last layer of polish comes from decisions that most generic tutorials skip.
These aren't “secret tricks.” They're judgment calls. The best advanced audio mixing techniques don't call attention to themselves. They subtly shape the listener's experience, which is exactly why they matter for creators who want a more premium sound.
De-essing and spectral restraint
A polished voice still needs edge control.
De-essing targets the sharp “s” and “sh” sounds that become grating on earbuds and phone speakers. The mistake is taking too much out. Overdo it and the speaker starts sounding lispy or dull. Done well, de-essing is almost invisible. The voice keeps its presence but stops spitting at the listener.
This is one of those moves that should be checked at lower monitoring levels. If the consonants still feel aggressive when the volume is down, they'll feel worse in typical listening environments.
Spatial effects for depth, not drama
Reverb and delay can help spoken content feel dimensional, but they have to stay subtle.
A little ambience can make a studio voice feel less dry, especially in branded video or narrative intros. Too much and the result feels distant, unfocused, or cheap. For podcasts, the safest use of spatial effects is often selective. Intro narration, transitions, or special segments can carry a touch more space than the main conversation.
This matters even more in adjacent content styles. Creators producing ambient, whisper-based, or texture-heavy formats often learn quickly that subtle processing decisions shape the entire identity of the piece. If that's part of your content mix, this article on how creators automate faceless ASMR videos is useful because it highlights how sonic texture and production workflow work together.
Bus processing and source separation
Advanced mixes often become cleaner when you stop processing tracks one by one and start shaping groups.
Dialogue buses let you make broad tonal or dynamic decisions across all voices while preserving track-specific fixes underneath. Music buses let you control the emotional bed of a show without fighting individual clips every few minutes. That bus-level thinking is one of the reasons professional sessions stay coherent.
For overlap problems, one of the most useful advanced approaches is inverse EQ matching. An engineer can capture the frequency profile of one source and apply an inverted version of that curve to another source, creating space without relying only on volume changes, as described in this walkthrough of inverse EQ matching for masking control. In plain English, if a voice and music bed are stepping on each other, you don't always need to just turn the music down. You can shape it to get out of the voice's way.
A few places this helps:
- Voice over music beds: Preserve energy while improving intelligibility.
- Two similar voices: Separate tonal centers slightly so each speaker reads more clearly.
- Layered intros: Keep narration present when sound design builds underneath it.
For creators interested in capturing cleaner source material before the mix stage, Flexwork's piece on advanced recording techniques for podcast sound quality is a smart companion read.
A signature sound usually comes from restraint. The mix feels expensive because nothing is fighting for attention.
Loudness and final delivery
Mastering for podcast and video platforms is partly technical, partly practical.
You do need to pay attention to LUFS, because perceived loudness and platform normalization affect how your content lands. However, creators often get lost in the numbers and forget the actual goal. A mix should feel controlled, clear, and durable across Spotify, Apple Podcasts, YouTube, and social clips. If chasing louder output crushes the voice, raises distortion, or makes breath noise jump forward, it isn't helping.
The better approach is simple. Build a balanced mix first. Control peaks. Keep speech intelligible. Then finalize loudness in a way that preserves tone and dynamics instead of sacrificing them.
Elevate Your Brand Beyond the Waveform
A viewer finds your show through a 30-second social clip. They do not see your full set, your episode structure, or the care behind the long-form edit. They hear your voice, the way the music sits under it, and whether the whole piece feels finished. That first impression often becomes the brand impression.
At the studio level, mixing is not only about fixing problems in a single episode. It is how creators build repeatable sonic cues that travel across formats. The same vocal tone, intro treatment, loudness discipline, and transition style can carry from a full YouTube interview to a teaser on Instagram, a pre-roll ad, or a sponsor read. Over time, that consistency makes your content recognizable before a logo even appears.
What a recognizable sound system does for your brand
The strongest creator brands usually have audio choices that stay stable even as the content expands. That does not mean every piece sounds identical. It means the fundamentals stay consistent enough that the audience learns what “you” sounds like.
A defined audio identity helps in a few concrete ways:
- Social clips feel connected to the main show: The voice sits in a familiar way, so short-form content still sounds like part of the same brand.
- Ad creative feels more premium: Reads, stingers, and music transitions match the standard of the flagship content.
- New formats launch faster: Once the mix framework is set, a webinar, trailer, or bonus episode does not need to be reinvented from scratch.
- Teams make better creative decisions: Editors, producers, and freelancers have a sonic reference instead of guessing.
Professional mixing proves its worth for podcasters and video creators. Music tutorials usually stop at “make it sound good.” Brand-focused post-production asks a different question. What should your audience hear again and again so your content feels familiar, expensive, and trustworthy across every touchpoint?
That answer often includes more than EQ and compression. It includes standardizing intros, deciding how aggressive your vocal processing should be, setting rules for music balance, and building reusable assets that support the mix instead of fighting it. If you are shaping that broader identity, Flexwork's guide on building your podcast brand with custom studio assets shows how the visual and sonic systems should work together.
Good creators publish episodes. Strong brands build recall. Your audio should help people recognize your work in a feed, in an ad slot, and in a clipped repost without needing a second look.
If you're ready to make your show sound as polished as it looks, book a session with Flexwork Podcast Studios. Whether you need a controlled recording environment, post-production support, or a more complete content workflow, the goal is simple: clearer dialogue, stronger presentation, and a brand experience that holds up the moment someone presses play.


